
LLM Concepts Intuition
Large language models use self-attention, tokenization, embeddings, and optimization techniques to process text efficiently. Learn 25 key concepts behind modern AI.


🔹 Introduction: Understanding the Core Concepts Behind Large Language Models
In the world of artificial intelligence, large language models (LLMs) have revolutionized how machines understand and generate human-like text. These models, built on neural networks and deep learning, rely on a series of fundamental principles that make them capable of reasoning, writing, and problem-solving at an unprecedented scale. From the Transformer architecture, which enables parallel processing of text, to self-attention mechanisms that allow AI to capture meaning across long sentences, every aspect of LLMs has been designed to optimize efficiency and accuracy. Tokenization breaks down words into smaller, manageable units, while embeddings help AI understand the relationships between different words. These foundational components form the building blocks of modern AI models like GPT-4, DeepSeek, and Claude.
Beyond the fundamentals, cutting-edge optimization techniques further enhance the performance of LLMs. Multi-head attention and mixture-of-experts models selectively focus on different aspects of language, making AI smarter while keeping computations efficient. Gradient descent and backpropagation enable AI to refine itself through learning, while dropout and layer normalization ensure stability during training. As models grow in size and complexity, additional innovations such as KV caching, long-context processing, and reinforcement learning with human feedback (RLHF) allow AI to generate coherent, context-aware responses while maintaining efficiency. In this article, we explore 25 essential concepts that drive the power of large language models, breaking them down into intuitive explanations to help anyone—whether a beginner or an AI enthusiast—understand how modern AI works.
Concepts Intuition Explained
1️⃣ Tokenization

🔹 Technical Definition (Precise & Accurate)
Tokenization is the process of breaking text into smaller subword units (tokens) so that it can be processed by a neural network. This can be done using Byte-Pair Encoding (BPE), WordPiece, or SentencePiece methods.
🔹 What Is It For? Why Is It Important?
✅ Allows AI to process text efficiently – Computers don’t understand whole sentences, so they need words split into manageable pieces.
✅ Handles rare and new words – Instead of memorizing every word, tokenization breaks words into subwords (e.g., "unhappiness" → ["un", "happiness"]).
✅ Improves translation and text generation – Helps AI work with multiple languages and complex vocabulary.
✅ Essential for all NLP models – Without tokenization, AI couldn’t understand human language.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you're learning a new language. If someone says a long, complicated word, you break it down into smaller parts to understand it better.
For example:
The word "unhappiness" becomes ["un", "happiness"].
The word "walking" becomes ["walk", "ing"].
AI does the same thing when processing text!
💡 Breaking Down the Definition:
“Breaking text into smaller subword units” → AI doesn’t read whole words but small chunks for better understanding.
“So it can be processed by a neural network” → AI needs input in numerical form to understand language.
“Byte-Pair Encoding (BPE), WordPiece, SentencePiece” → Different techniques help AI handle different types of text.
“Essential for AI to understand text” → Without tokenization, AI would be completely lost when dealing with language.
2️⃣ Embeddings

🔹 Technical Definition (Precise & Accurate)
Embeddings are high-dimensional vector representations of words or tokens, where similar words have closer numerical values in an embedding space, allowing models to understand semantic relationships between words.
🔹 What Is It For? Why Is It Important?
✅ Transforms words into numbers AI can understand – Computers can't process words directly, so embeddings turn words into meaningful numerical representations.
✅ Captures meaning and relationships – Similar words (like "king" and "queen") are mathematically closer in the embedding space, improving AI understanding.
✅ Essential for NLP models – Without embeddings, AI wouldn’t know that “apple” (fruit) and “orange” (fruit) are related.
✅ Improves search and recommendation systems – Helps AI find similar items, like products or documents.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you have a map of words, where similar words are closer together and unrelated words are far apart.
For example:
“Cat” and “dog” are close together.
“Cat” and “car” are far apart.
“Paris” and “France” are close together.
💡 Breaking Down the Definition:
“High-dimensional vector representations” → Every word becomes a set of numbers that encode its meaning.
“Similar words have closer numerical values” → Words with related meanings are mathematically close.
“Embedding space” → A virtual map of word meanings.
“Allows models to understand semantic relationships” → AI can detect similarities and context in words.
3️⃣ Self-Attention Mechanism

🔹 Technical Definition (Precise & Accurate)
The self-attention mechanism allows each token (word) in a sentence to compare itself with every other token, dynamically adjusting its importance based on context, capturing long-range dependencies and contextual meaning.
🔹 What Is It For? Why Is It Important?
✅ Solves word ambiguity – Words like "bank" (riverbank or money bank?) are understood based on sentence context.
✅ Handles long-range dependencies – Captures relationships between words far apart in a sentence.
✅ Replaces old memory-based models – Unlike RNNs, which forget older words, self-attention sees everything at once.
✅ Core mechanism behind GPT models – Without self-attention, modern chatbots and translators wouldn’t work well.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you're trying to figure out who "he" refers to in:
"John went to the park. He bought ice cream."
Your brain looks back and realizes "he" means John. That’s self-attention—the AI checks all words before deciding how important they are.
💡 Breaking Down the Definition:
“Each token compares itself with every other token” → Every word checks how it relates to every other word.
“Dynamically adjusting its importance” → AI learns which words are meaningful and which are not.
“Capturing long-range dependencies” → AI knows "he" refers to "John," even if they are far apart.
“Contextual meaning” → Helps AI understand sentences better, improving its reasoning.
4️⃣ Transformer Architecture
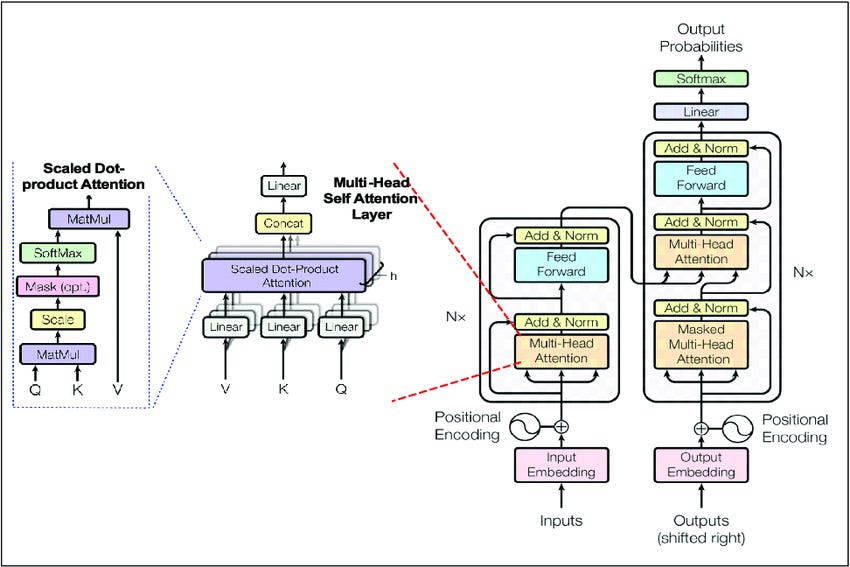
🔹 Technical Definition (Precise & Accurate)
The Transformer architecture is a deep learning model designed for processing sequential data using self-attention mechanisms and feedforward layers, rather than traditional recurrent or convolutional methods.
🔹 What Is It For? Why Is It Important?
✅ Processes language efficiently – Unlike older models like RNNs, Transformers process entire sentences at once, making them faster and better at understanding long texts.
✅ Foundation of modern AI models – GPT-4, DeepSeek, and Claude are all built on Transformers.
✅ Great for long-context tasks – Can recall information across longer documents, improving translation, chatbots, and summarization.
✅ Parallelization speeds up training – Instead of reading words one at a time like humans, Transformers analyze everything at once, making them incredibly fast.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re reading a book, but instead of reading one word at a time, you scan the whole page instantly and figure out which words are most important. That’s what a Transformer does—it looks at all words at once, instead of reading them sequentially.
💡 Breaking Down the Definition:
“Self-attention” → It focuses on important words while ignoring unimportant ones.
“Processes text all at once” → It doesn't read word-by-word but looks at all words together.
“Feedforward layers” → After processing relationships between words, it passes the information through multiple steps to refine the answer.
“Instead of traditional sequential models” → Unlike RNNs, which slowly process words in order, Transformers do everything in parallel for speed.
🔹 Image Breakdown
1. Scaled Dot-Product Attention (Leftmost Part)
This is the fundamental mechanism of attention in transformers. It allows the model to determine how much focus each word (or token) should give to other words in the sequence. This is particularly useful for capturing long-range dependencies in text.
Breakdown of the Process:
Query (Q), Key (K), and Value (V):
Every word in the sequence is transformed into these three different vector representations.
Query (Q) represents what we are searching for.
Key (K) represents the words being compared to the query.
Value (V) contains the actual word information that will be used for the output. Multiplying by V ensures that the output contains actual word meanings weighted by their importance.
MatMul (Matrix Multiplication):
The dot product of the query (Q) and key (K) matrices is computed.
This results in a similarity score, indicating how relevant each word (key) is to the current word (query).
Scale:
The similarity scores are divided by the square root of the dimension of K.
This is done to prevent large values, which could lead to unstable gradients and overly sharp softmax distributions.
Mask (optional):
Used primarily in decoders to prevent looking at future words.
Ensures the model can only attend to words that have already been processed.
Softmax:
Converts the scaled attention scores into a probability distribution.
Higher scores indicate a stronger focus on certain words.
MatMul with V:
The softmax scores are used to weight the value (V) matrix.
This results in a refined representation of the input based on contextual importance.
2. Multi-Head Self-Attention Layer (Middle Part)
Instead of computing attention once, the Transformer uses multiple attention heads in parallel.
Each head learns different types of relationships between words.
The results from multiple heads are concatenated and passed through a linear transformation.
Why Multiple Heads?
A single attention mechanism might focus too much on a single aspect of the input.
Multiple heads allow the model to capture different dependencies (e.g., one head may focus on subject-verb relationships, while another captures noun-adjective associations).
This enhances the richness of the learned representations.
How Multi-Head Attention Works:
Each head gets its own Q, K, and V matrices, obtained by applying different linear transformations to the input.
Each head applies scaled dot-product attention independently.
The outputs from all heads are concatenated.
A final linear transformation combines the multi-head outputs into a single tensor.
3. Transformer Encoder-Decoder Blocks (Rightmost Part)
This part represents the full encoder-decoder structure of the Transformer.
Positional Encoding
Since Transformers don’t process input sequentially (like RNNs), they lack an inherent sense of word order.
To fix this, a positional encoding is added to the input embeddings.
Positional encodings are sine and cosine functions that inject order information into word representations.
Input Embedding
Converts tokens (words, subwords, or characters) into dense vector representations.
These embeddings are learned during training.
Multi-Head Attention in the Encoder
The encoder uses self-attention to process all input tokens simultaneously.
Each word in the input attends to all other words, determining how much importance each should have in the final representation.
Masked Multi-Head Attention in the Decoder
The decoder needs to generate output one token at a time.
To prevent cheating (i.e., looking at future tokens), a mask is applied.
This ensures that predictions are only based on previously generated words.
Add & Norm (Residual Connections)
Each layer is followed by layer normalization to stabilize training.
Residual connections help prevent vanishing gradients and allow information to flow more smoothly.
Feed Forward Network (FFN)
Each layer has a position-wise feed-forward network.
It consists of two linear transformations with a ReLU activation function.
This helps introduce non-linearity and improves feature learning.
Output Embedding & Softmax
After processing through multiple layers, the output is passed through a final linear transformation.
A softmax layer converts this into a probability distribution over the vocabulary.
The token with the highest probability is selected as the next predicted word.
5️⃣ Activation Functions

🔹 Technical Definition (Precise & Accurate)
Activation functions are mathematical functions applied to a neuron’s output to introduce non-linearity, enabling deep networks to learn complex patterns rather than just linear relationships.
🔹 What Is It For? Why Is It Important?
✅ Prevents AI from being a simple calculator – Without activation functions, AI would only learn straight-line relationships, making it useless for real-world problems.
✅ Enables deep learning – Helps networks learn curved, complex patterns like human vision and language.
✅ Different activations for different tasks – Some functions work better for text (ReLU, Softmax), others for images (Tanh, Sigmoid).
✅ Essential for decision-making in AI – Without activation functions, AI would always give linear, predictable answers.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re adjusting the volume on a speaker.
If the volume button only allowed "on" or "off", it wouldn’t be useful.
Instead, you need smooth control over the volume—this is what activation functions do.
💡 Breaking Down the Definition:
“Mathematical functions applied to neurons” → A formula decides how strongly a neuron should "fire."
“Introduce non-linearity” → Helps AI learn complex patterns, not just straight lines.
“Deep networks learn better” → AI can recognize faces, objects, or meaning in text instead of just simple numbers.
“Instead of just linear relationships” → AI understands curves and complex decision-making.
6️⃣ Positional Encoding

🔹 Technical Definition (Precise & Accurate)
Positional encoding is a numerical representation added to word embeddings in Transformer models to preserve the order of words in a sentence, since Transformers process all tokens in parallel and lack inherent sequential awareness.
🔹 What Is It For? Why Is It Important?
✅ Gives Transformers a sense of word order – Since Transformers process words all at once, they need a way to understand word sequence.
✅ Prevents loss of meaning in sentences – Without positional encoding, “John loves Mary” and “Mary loves John” would be treated the same.
✅ Key to NLP tasks like translation and summarization – Ensures logical word placement when AI generates text.
✅ Avoids the need for sequential processing – Older models like RNNs had to process text word by word, making them slow.
🔹 Intuition: How It Works (Layman Explanation)
Imagine reading a shuffled recipe—the ingredients are correct, but if the steps are out of order, it doesn’t make sense!
Positional encoding adds invisible numbers to each word so the AI knows the correct order.
💡 Breaking Down the Definition:
“Numerical representation added to word embeddings” → Each word gets a position number.
“Preserve the order of words in a sentence” → Helps AI keep sentence meaning intact.
“Transformers process tokens in parallel” → Unlike RNNs, which process one word at a time.
“Lack inherent sequential awareness” → Transformers don’t know order unless we tell them.
7️⃣ Multi-Head Attention

🔹 Technical Definition (Precise & Accurate)
Multi-head attention is an extension of self-attention where multiple attention mechanisms (heads) run in parallel, each focusing on different aspects of the sentence, improving contextual understanding.
🔹 What Is It For? Why Is It Important?
✅ Improves AI comprehension – Helps AI focus on different parts of a sentence at once.
✅ Prevents loss of meaning – Without multi-head attention, AI might misinterpret complex sentences.
✅ Boosts performance in translation, summarization, and chatbots – Allows AI to analyze multiple relationships simultaneously.
✅ Essential for deep learning models like GPT and BERT – Enables faster, smarter AI responses.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re analyzing a book, but instead of reading one aspect at a time, you assign different people to focus on different parts:
One person looks at character relationships.
Another tracks the timeline of events.
A third studies the themes.
All these perspectives combine to give a complete understanding. Multi-head attention does the same thing—it analyzes multiple aspects of text simultaneously.
💡 Breaking Down the Definition:
“Multiple attention mechanisms (heads) run in parallel” → AI focuses on many details at once.
“Each focusing on different aspects of the sentence” → One attention head might track subject-object relationships, another verbs, etc.
“Improves contextual understanding” → AI understands text better than if it used only one focus.
“Prevents loss of meaning” → Makes AI more accurate in language tasks.
8️⃣ Layer Normalization

🔹 Technical Definition (Precise & Accurate)
Layer normalization is a technique used in deep learning to stabilize training by normalizing activations within each layer, preventing gradient explosions and improving convergence speed.
🔹 What Is It For? Why Is It Important?
✅ Prevents unstable training – Stops AI from learning too fast or too slow, which can break models.
✅ Helps deep networks converge faster – Ensures AI models reach optimal performance quickly.
✅ Reduces the risk of exploding/vanishing gradients – Keeps AI from getting stuck during learning.
✅ Improves generalization – AI performs better on new, unseen data.
🔹 Intuition: How It Works (Layman Explanation)
Imagine baking a cake—if some ingredients are too strong (too much salt, too little sugar), the cake will taste bad.
Layer normalization adjusts ingredient amounts, so every layer in AI has balanced values, making learning more stable.
💡 Breaking Down the Definition:
“Stabilizes training” → Keeps AI from learning too fast or too erratically.
“Normalizing activations within each layer” → Adjusts values so they don’t go too high or low.
“Preventing gradient explosions” → Stops AI from making wild updates that break learning.
“Improving convergence speed” → AI learns efficiently, reaching the best settings faster.
9️⃣ Feedforward Networks (FFN)
 | by Mohammed Terry-Jack | Medium")
🔹 Technical Definition (Precise & Accurate)
A feedforward network (FFN) is a fully connected layer within a Transformer block that applies non-linearity and feature transformation to improve the model’s ability to learn complex representations.
🔹 What Is It For? Why Is It Important?
✅ Enhances pattern recognition – FFNs help the model refine relationships between words.
✅ Adds non-linearity – Prevents the AI from learning only simple patterns, enabling it to understand complex ideas.
✅ Speeds up processing – Unlike attention layers, FFNs work independently on each word, allowing for faster computations.
✅ Essential for NLP tasks – Without FFNs, the model wouldn’t understand hierarchical relationships in text.
🔹 Intuition: How It Works (Layman Explanation)
Imagine your brain processing a math problem. After reading the question, you break it down, solve small parts, then combine them into a final answer.
A feedforward network does the same—it processes information, refines it, and outputs a smarter representation.
💡 Breaking Down the Definition:
“Fully connected layer” → Every neuron is connected to all inputs.
“Applies non-linearity” → Ensures AI can handle complex relationships, not just simple patterns.
“Feature transformation” → AI converts words into better numerical representations.
“Improves representation learning” → AI understands deeper meaning behind words.
🔟 Residual Connections (Skip Connections)

🔹 Technical Definition (Precise & Accurate)
Residual connections, or skip connections, are shortcuts in deep neural networks that bypass certain layers, allowing raw input information to pass through unmodified, preventing vanishing gradients and improving training stability.
🔹 What Is It For? Why Is It Important?
✅ Prevents vanishing gradients – Ensures deep networks can still learn effectively.
✅ Stabilizes training – Helps Transformers train faster and more efficiently.
✅ Preserves original input features – Some information shouldn’t be altered too much, and skip connections help retain it.
✅ Improves accuracy in deep networks – Essential for very deep models like GPT-4, making them more stable and accurate.
🔹 Intuition: How It Works (Layman Explanation)
Imagine writing a long essay and revising each paragraph multiple times. Instead of rewriting everything, you keep the good parts and refine only what’s necessary.
Skip connections do the same for AI, allowing it to keep the original input while refining certain aspects.
💡 Breaking Down the Definition:
“Shortcuts in deep neural networks” → Lets information skip layers if needed.
“Bypass certain layers” → Some data is passed forward untouched.
“Preventing vanishing gradients” → Ensures AI keeps learning even with deep layers.
“Improving training stability” → Makes AI train faster and avoid errors.
1️⃣1️⃣ Pretraining on Large Corpora

🔹 Technical Definition (Precise & Accurate)
Pretraining is the process of training an AI model on massive, diverse datasets (books, Wikipedia, Common Crawl, etc.) in an unsupervised manner, allowing it to learn general language patterns before fine-tuning on specific tasks.
🔹 What Is It For? Why Is It Important?
✅ Gives AI a broad understanding of language – AI learns grammar, facts, and common sense before specialized training.
✅ Reduces need for human-labeled data – Instead of requiring labels, AI learns from raw text.
✅ Improves performance across many tasks – AI trained this way can be fine-tuned for multiple applications (chatbots, translation, etc.).
✅ Foundation of all modern LLMs – GPT-4, DeepSeek, and Claude all rely on pretraining.
🔹 Intuition: How It Works (Layman Explanation)
Imagine learning a new sport.
Before playing a real game, you watch matches, practice drills, and learn the rules.
This "pretraining" prepares you for real matches.
Similarly, AI reads billions of words first before fine-tuning for specific jobs like answering questions.
💡 Breaking Down the Definition:
“Massive, diverse datasets” → AI learns from millions of books, websites, and documents.
“Unsupervised manner” → AI teaches itself without direct human corrections.
“Learns general language patterns” → AI understands words, grammar, and facts before fine-tuning.
“Before fine-tuning on specific tasks” → Later, AI is trained for specific applications like coding or medical diagnoses.
1️⃣2️⃣ Unsupervised Learning (Self-Supervised Learning)
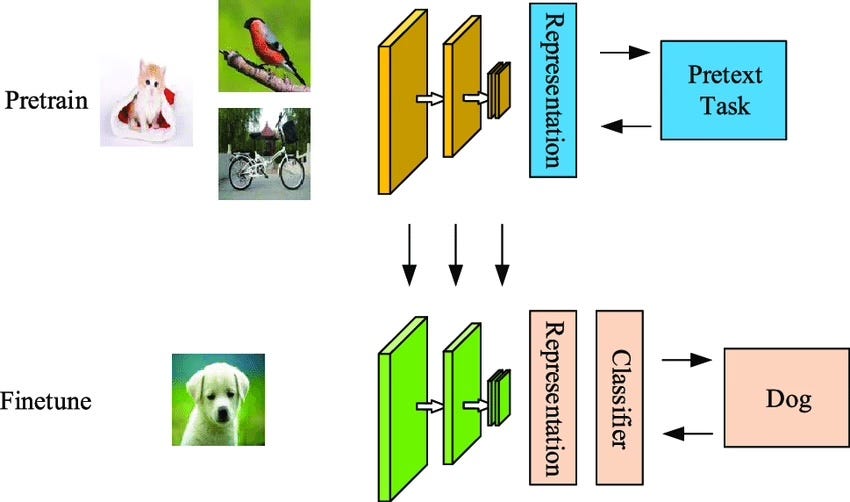
🔹 Technical Definition (Precise & Accurate)
Unsupervised learning is a machine learning method where a model learns patterns and structures from raw data without labeled examples, allowing it to discover relationships independently.
🔹 What Is It For? Why Is It Important?
✅ Removes reliance on human-labeled data – AI can learn from raw text without needing manually labeled answers.
✅ Helps AI generalize across tasks – The model learns fundamental language skills before specific training.
✅ Powers modern LLMs like GPT-4 – All major AI models use this technique for large-scale learning.
✅ Essential for discovering unknown patterns – Used in scientific research, data clustering, and anomaly detection.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re learning a new language by watching movies—you don’t have a teacher telling you the meanings of words, but over time, you pick up patterns naturally.
That’s how unsupervised learning works—AI figures out language rules and patterns by itself without needing labeled data.
💡 Breaking Down the Definition:
“Learns patterns and structures from raw data” → AI analyzes text to discover patterns on its own.
“Without labeled examples” → No one explicitly tells AI which answers are correct.
“Allows it to discover relationships independently” → AI finds hidden connections in data without human intervention.
“Essential for LLMs like GPT-4” → Without this, AI couldn’t scale to trillions of words.
1️⃣3️⃣ Next-Token Prediction

🔹 Technical Definition (Precise & Accurate)
Next-token prediction is a language modeling technique where an AI model predicts the most likely next word (or token) in a sequence, based on prior context, using probability distributions.
🔹 What Is It For? Why Is It Important?
✅ Core mechanism behind GPT models – Every word AI generates is predicted one token at a time.
✅ Enables realistic AI text generation – Models like GPT-4 generate responses by predicting the next word repeatedly.
✅ Allows AI to complete and generate text smoothly – Without this, AI couldn’t continue sentences meaningfully.
✅ Used in autocomplete, chatbots, and writing assistants – Helps AI predict user intentions and assist with writing tasks.
🔹 Intuition: How It Works (Layman Explanation)
Imagine playing a guess-the-next-word game with a friend:
You say, "The sun is very..."
Your friend predicts, "bright" or "hot", based on what makes the most sense.
AI does the same thing—it looks at what came before and picks the next word based on probability.
💡 Breaking Down the Definition:
“Language modeling technique” → AI learns how sentences are typically structured.
“Predicts the most likely next word” → AI picks the best word based on previous words.
“Uses probability distributions” → AI assigns probabilities to multiple words and picks the most likely one.
“Repeats this process to generate full text” → Each new word is predicted one by one, creating complete sentences.
1️⃣4️⃣ Gradient Descent & Backpropagation

🔹 Technical Definition (Precise & Accurate)
Gradient descent is an optimization algorithm that updates the weights of a neural network by calculating the direction of steepest loss reduction, while backpropagation computes and distributes error gradients to adjust weights layer by layer.
🔹 What Is It For? Why Is It Important?
✅ Helps AI learn by correcting mistakes – AI adjusts its internal weights every time it makes a wrong prediction.
✅ Prevents models from making the same errors repeatedly – Ensures AI gets better with each training step.
✅ Optimizes deep learning models – Without gradient descent, AI models wouldn't know how to improve.
✅ Used in all deep learning systems – Everything from image recognition to chatbots relies on gradient descent.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re hiking down a mountain in the fog, trying to reach the lowest point:
You take small steps downhill to avoid falling.
If you step in the wrong direction, you adjust course.
Eventually, you reach the lowest point (best solution).
AI does the same thing—it gradually "steps" toward the best solution by adjusting weights.
💡 Breaking Down the Definition:
“Optimization algorithm” → A method that helps AI improve over time.
“Updates weights of a neural network” → AI adjusts its internal settings to make better predictions.
“Direction of steepest loss reduction” → AI takes steps toward lower errors.
“Backpropagation distributes error gradients” → Errors are sent backward through the network to fix mistakes.
1️⃣5️⃣ Optimizers (Adam, AdamW, SGD)

🔹 Technical Definition (Precise & Accurate)
Optimizers are algorithms used in neural networks to adjust model weights efficiently during training. Popular types include:
SGD (Stochastic Gradient Descent) – Adjusts weights using a random sample of data to speed up training.
Adam (Adaptive Moment Estimation) – Combines momentum and adaptive learning rates to optimize faster.
AdamW (Adam with Weight Decay) – A more stable version of Adam, reducing overfitting.
🔹 What Is It For? Why Is It Important?
✅ Speeds up AI training – Without optimizers, models would take too long to learn.
✅ Prevents AI from getting stuck – Helps AI find the best solution without unnecessary detours.
✅ Balances speed vs. accuracy – Different optimizers work better for different AI applications.
✅ Used in all deep learning models – Optimizers are crucial for training large AI models like GPT-4.
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re riding a bike downhill:
If you go too fast, you might lose control.
If you go too slow, it takes forever to get down.
The right optimizer helps you descend at the perfect speed—fast enough to be efficient but controlled enough to avoid mistakes.
💡 Breaking Down the Definition:
“Algorithms used in neural networks” → AI needs a method to update itself efficiently.
“Adjust model weights efficiently” → AI tweaks numbers to make better predictions.
“Different optimizers work better for different problems” → Some are faster, others are more stable.
“Helps models learn faster and generalize better” → AI trains efficiently without overfitting.
1️⃣6️⃣ Loss Functions

🔹 Technical Definition (Precise & Accurate)
A loss function is a mathematical function that measures how far an AI’s predictions are from the actual results, guiding weight adjustments during training.
🔹 What Is It For? Why Is It Important?
✅ Helps AI measure mistakes – Without a loss function, AI wouldn’t know how wrong it is.
✅ Guides learning and improvement – The AI adjusts its internal settings based on loss values.
✅ Essential for deep learning – Every AI model uses a loss function to optimize predictions.
✅ Different loss functions for different tasks – Some are used for classification (cross-entropy), some for regression (MSE).
🔹 Intuition: How It Works (Layman Explanation)
Imagine you’re practicing archery:
You shoot an arrow at a target.
If you miss the bullseye, you measure how far off you are.
Next time, you adjust your aim based on that feedback.
AI does the same—it measures its errors and adjusts to improve next time.
💡 Breaking Down the Definition:
“Mathematical function” → A formula tells AI how wrong it was.
“Measures how far predictions are from actual results” → AI compares its guess to the real answer.
“Guides weight adjustments during training” → AI fine-tunes itself to make better guesses.
“Essential for optimizing accuracy” → Without loss functions, AI wouldn’t improve.
1️⃣7️⃣ Dropout

🔹 Technical Definition (Precise & Accurate)
Dropout is a regularization technique used in deep learning that randomly deactivates a subset of neurons during training, preventing overfitting and improving generalization to unseen data.
🔹 What Is It For? Why Is It Important?
✅ Prevents overfitting – Stops AI from memorizing training data instead of learning real patterns.
✅ Encourages diverse feature learning – Forces AI to use different parts of the network, making it more robust.
✅ Improves generalization – Models trained with dropout perform better on new, unseen data.
✅ Used in many deep learning models – Helps AI remain flexible and avoid learning "shortcuts."
🔹 Intuition: How It Works (Layman Explanation)
Imagine you're studying for an exam:
If you highlight every sentence in your textbook, nothing stands out.
Instead, you hide parts of the text and test yourself to ensure you truly understand the material.
Dropout does the same—it randomly removes some neurons during training so that AI learns in a more balanced way.
💡 Breaking Down the Definition:
“Randomly deactivates a subset of neurons” → Some AI connections are turned off temporarily to encourage better learning.
“Prevents overfitting” → Forces AI to generalize instead of memorizing training examples.
“Encourages diverse feature learning” → AI must learn different aspects of data instead of relying on a few strong neurons.
“Improves generalization” → AI performs better on new data instead of just remembering training examples.
1️⃣8️⃣ Reinforcement Learning with Human Feedback (RLHF)

🔹 Technical Definition (Precise & Accurate)
Reinforcement Learning with Human Feedback (RLHF) is a training approach where AI is fine-tuned using human-generated preferences and reward models to align responses with human values and improve output quality.
🔹 What Is It For? Why Is It Important?
✅ Aligns AI responses with human expectations – Without RLHF, AI-generated answers may sound unnatural or biased.
✅ Improves chatbot accuracy and helpfulness – AI learns to prioritize answers that humans prefer.
✅ Reduces harmful or unethical outputs – Ensures AI avoids generating harmful or misleading content.
✅ Used in ChatGPT, DeepSeek, Claude, etc. – Without RLHF, LLMs would struggle with nuanced responses.
🔹 Intuition: How It Works (Layman Explanation)
Imagine training a robot chef:
The robot tries different recipes and serves them to human taste-testers.
Humans give feedback on what tastes good and what needs improvement.
The robot adjusts its recipes based on human preferences.
Over time, it learns to cook food that humans love.
💡 Breaking Down the Definition:
“Fine-tuned using human-generated preferences” → Humans rate AI responses to guide its learning.
“Uses reward models” → AI learns which responses are preferred based on human feedback.
“Aligns responses with human values” → AI avoids giving robotic, insensitive, or harmful answers.
“Improves output quality” → AI becomes more natural, nuanced, and safe for conversation.
1️⃣9️⃣ Proximal Policy Optimization (PPO)

🔹 Technical Definition (Precise & Accurate)
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm that fine-tunes AI models by iteratively improving responses while maintaining stability, preventing extreme behavior shifts in training.
🔹 What Is It For? Why Is It Important?
✅ Prevents AI from making drastic learning jumps – Ensures smooth, stable learning.
✅ Used in RLHF for AI fine-tuning – Helps AI balance exploration (trying new responses) and exploitation (using what works best).
✅ Improves efficiency in reinforcement learning – More efficient than older algorithms like TRPO (Trust Region Policy Optimization).
✅ Essential for chatbots like ChatGPT – Fine-tunes how AI responds to human input.
🔹 Intuition: How It Works (Layman Explanation)
Imagine teaching a dog tricks:
You reward small improvements instead of expecting a perfect backflip right away.
If the dog improves slightly, you reinforce that behavior.
If it tries something completely random, you guide it back toward good behavior.
PPO does the same for AI—it fine-tunes learning in small, controlled steps.
💡 Breaking Down the Definition:
“Fine-tunes AI models iteratively” → AI learns gradually over multiple cycles.
“Maintains stability” → AI doesn’t make extreme, sudden changes in behavior.
“Balances exploration and exploitation” → AI tries new things while sticking to what works.
“Used in RLHF to optimize AI responses” → Helps AI get better at responding to humans.
2️⃣0️⃣ Mixture-of-Experts (MoE) Models

🔹 Technical Definition (Precise & Accurate)
Mixture-of-Experts (MoE) models are a deep learning architecture where multiple smaller expert networks specialize in different tasks, and only a subset of experts is activated per input, improving efficiency and scalability.
🔹 What Is It For? Why Is It Important?
✅ Reduces computation costs – Instead of running a giant model all the time, MoE activates only the necessary experts.
✅ Improves AI scalability – Allows LLMs to scale to trillions of parameters without insane hardware costs.
✅ Makes AI more specialized – Instead of one big brain, MoE has multiple smaller brains working together.
✅ Used in DeepSeek, GPT-4, and large AI models – MoE allows modern AI to process more information efficiently.
🔹 Intuition: How It Works (Layman Explanation)
Imagine a hospital with many doctors:
Instead of one doctor treating every disease, specialists handle specific cases.
A neurologist treats brain problems, a cardiologist handles heart issues, etc.
When a patient arrives, only the relevant doctors are called in instead of making every doctor review every case.
MoE works the same way—only the necessary "expert AI neurons" activate per task, saving resources.
💡 Breaking Down the Definition:
“Multiple smaller expert networks specialize in different tasks” → AI has specialized "mini-models" for different problems.
“Only a subset of experts is activated per input” → Instead of running the entire model, only relevant neurons activate.
“Improving efficiency and scalability” → AI becomes cheaper and faster while handling more complex tasks.
“Used in large models like DeepSeek and GPT-4” → Allows AI to grow while keeping computational costs manageable.
2️⃣1️⃣ Long-Context Processing (RoPE, ALiBi, RAG)
")
🔹 Technical Definition (Precise & Accurate)
Long-context processing refers to techniques that enable AI models to handle longer input sequences efficiently. Three main methods are:
RoPE (Rotary Positional Embeddings) – Helps models remember word order without fixed positional encodings.
ALiBi (Attention Linear Biases) – Adds a decreasing bias to distant words, reducing computation while preserving long-term dependencies.
RAG (Retrieval-Augmented Generation) – Allows AI to retrieve external documents dynamically to extend its knowledge.
🔹 What Is It For? Why Is It Important?
✅ Improves memory of long conversations – AI can now reference earlier parts of a conversation without forgetting.
✅ Reduces context window limitations – Enables longer documents, articles, and research papers to be processed.
✅ Speeds up processing – Reduces computational cost for handling long text efficiently.
✅ Essential for research, legal documents, and summarization – Helps AI work with complex, multi-step problems.
🔹 Intuition: How It Works (Layman Explanation)
Imagine trying to remember a long story:
RoPE: Instead of memorizing exact word positions, AI uses angles (like a rotating compass) to track relationships between words dynamically.
ALiBi: AI pays more attention to recent words but still considers older ones in a way that saves memory.
RAG: When AI forgets something, it looks it up in a book rather than relying purely on memory.
💡 Breaking Down the Definition:
“Helps models handle long input sequences” → AI can now read and understand longer documents.
“Reduces memory and computation overhead” → AI doesn’t have to store everything in memory at once.
“Enables AI to recall previous parts of text” → Allows AI to understand longer discussions.
“Used in legal, research, and chatbot applications” → Makes AI better for real-world tasks.
2️⃣2️⃣ Fine-Tuning vs. LoRA Adaptation
: Revolutionizing AI Fine-Tuning")
🔹 Technical Definition (Precise & Accurate)
Fine-tuning and LoRA (Low-Rank Adaptation) are methods for adapting AI models to specific tasks:
Fine-Tuning – The model is trained again on specialized data, modifying all its parameters.
LoRA – A lightweight method that adds a small number of trainable parameters, keeping the base model frozen while adjusting only specific layers.
🔹 What Is It For? Why Is It Important?
✅ Fine-tuning creates highly specialized AI – Best for medical, legal, or scientific AI models.
✅ LoRA makes AI adaptable and cheaper – Great for deploying AI on limited resources.
✅ Fine-tuning requires more computing power – LoRA is faster and more memory-efficient.
✅ Both methods allow AI to be personalized – Businesses use them to train AI for their specific needs.
🔹 Intuition: How It Works (Layman Explanation)
Think of learning a new skill:
Fine-Tuning: Like going back to school and re-learning everything from scratch for a new career.
LoRA: Like taking a short course—you keep your existing knowledge but learn a small set of new tricks.
💡 Breaking Down the Definition:
“Fine-tuning modifies all parameters” → AI completely retrains on new data.
“LoRA keeps the base model frozen” → AI only adjusts certain aspects, keeping the rest unchanged.
“Fine-tuning is best for large-scale retraining” → Used when AI needs deep specialization.
“LoRA is best for lightweight adaptations” → Saves computational cost while still improving AI performance.
2️⃣3️⃣ Model Pruning & Quantization

🔹 Technical Definition (Precise & Accurate)
Model pruning and quantization are techniques to reduce AI model size while maintaining efficiency:
Pruning – Removes unnecessary neurons or connections to speed up inference.
Quantization – Reduces the precision of model weights (e.g., from FP32 to FP8) to save memory and improve speed.
🔹 What Is It For? Why Is It Important?
✅ Speeds up AI inference – Allows AI to run faster on lower-end hardware.
✅ Reduces AI energy consumption – Useful for mobile devices, embedded systems, and cloud applications.
✅ Keeps AI models deployable at scale – Large LLMs like GPT-4 can be compressed without losing accuracy.
✅ Essential for AI efficiency in real-world applications – Used in edge AI, robotics, and real-time systems.
🔹 Intuition: How It Works (Layman Explanation)
Imagine packing for a vacation:
Pruning: You remove clothes you never wear to lighten your suitcase.
Quantization: Instead of packing large shampoo bottles, you bring small travel-sized ones.
AI does the same thing—it removes unnecessary parts and shrinks data representation to fit smaller devices.
💡 Breaking Down the Definition:
“Pruning removes unnecessary neurons” → AI keeps only the most useful parts.
“Quantization reduces weight precision” → AI compresses numbers to save space.
“Speeds up inference while maintaining accuracy” → AI runs faster without significant performance loss.
“Essential for deploying AI on mobile and cloud devices” → Enables AI to run in real-world environments.
2️⃣4️⃣ KV Caching for Faster Inference

🔹 Technical Definition (Precise & Accurate)
KV caching (Key-Value caching) is a technique used in autoregressive AI models that stores previously computed attention outputs, reducing redundant calculations and speeding up text generation.
🔹 What Is It For? Why Is It Important?
✅ Speeds up text generation – AI doesn’t have to recalculate previous words each time.
✅ Improves efficiency in large models – Used in GPT, DeepSeek, and other LLMs to enhance responsiveness.
✅ Reduces computational cost – AI requires less power to generate text in real-time.
✅ Essential for chatbots and virtual assistants – Helps AI answer quickly in conversations.
🔹 Intuition: How It Works (Layman Explanation)
Imagine writing a long essay:
Instead of rereading everything from the beginning each time, you remember what you’ve already written.
KV caching lets AI store earlier words, so it only focuses on generating the next ones.
💡 Breaking Down the Definition:
“Stores previously computed attention outputs” → AI remembers past work instead of recalculating.
“Reduces redundant calculations” → AI works more efficiently instead of starting over.
“Speeds up text generation” → Helps AI respond faster.
“Essential for chatbots and virtual assistants” → Allows AI to maintain fast, natural conversations.
2️⃣5️⃣ Memory-Augmented Transformers
: Secret behind the success of DeepSeek Large Language Models | by Nagur Shareef Shaik | Jan, 2025 | Medium")
🔹 Technical Definition (Precise & Accurate)
Memory-Augmented Transformers use external memory banks or dynamic recall mechanisms to extend AI’s memory beyond a fixed context window, allowing better recall of past interactions and stored knowledge.
🔹 What Is It For? Why Is It Important?
✅ Enhances long-term AI memory – Helps AI remember previous discussions beyond the context window.
✅ Improves reasoning and multi-step problem-solving – AI remembers prior logic and builds on it.
✅ Used in advanced AI models – Helps chatbots and research assistants retain long-term knowledge.
✅ Key for AI assistants and research applications – Ensures AI doesn't forget user interactions quickly.
🔹 Intuition: How It Works (Layman Explanation)
Imagine AI as a detective taking notes on a case:
Instead of forgetting details after each conversation, it stores key facts and recalls them later.
AI remembers context across multiple interactions, leading to better responses over time.
💡 Breaking Down the Definition:
“Uses external memory banks” → AI stores information beyond its usual limits.
“Extends AI’s recall ability” → AI can remember facts for longer.
“Improves reasoning across multiple interactions” → AI doesn’t reset its knowledge every time.
“Used in chatbots, research, and knowledge-based AI” → Makes AI smarter and more useful.
 | A guest post by
|